Third-party data collaboration, while essential to growth, carries inherent risks: Data breaches, regulatory missteps, and unreliable customer information can all significantly disrupt your operations. To address these risks, companies are increasingly turning sidecars, also known as “compliance sidecars” or “cross-party active metadata,” to better manage data exchange with third parties. This article explains everything your business needs to know about sidecars, a powerful tool for ensuring trustworthy data exchange with partners and third parties.
Table of Contents
What are sidecars?
Sidecars refer to key business details (i.e., active metadata) that travel with data across external systems, carrying information about its provenance, compliance, timeliness, and other important characteristics. Sidecars are crucial for managing many of the risks associated with exchanging data with external parties. And while regulatory compliance is certainly an important component, it’s only one of the many elements this key metadata conveys. As data moves between parties and across systems, sidecars provide the receiving party with critical information such as:
- Origin: Where did this data come from?
- Timeliness: When was it last updated?
- Suitability for use: How can this data be used responsibly?
Importantly, sidecars aren't limited to data transfers between two parties. They can accumulate information as data travels from company to company to company. This ability to handle multi-stage journeys (technically called "transitive closure") is vital because it ensures the original source of the data is always preserved, not just the most recent owner. Unlike traditional data sharing, sidecars allow information to be updated as it travels between different parties. This means that businesses can add restrictions or details specific to each recipient’s needs. For example, data passing through a regulatory filter might be flagged for stricter usage compared to the original version. Sidecars also support downstream changes to data sets, such as cleansing, enrichment, combining, etc., which makes multi-hop sidecar tracking more complex yet even more critical.
Common characteristics of sidecars
While companies can customize sidecars around specific partner or industry data-sharing needs, they typically include the following information:
- Source: Origin of the data, including contact details and specifics such as a clinical trial source for pharmaceutical data. For multi-source data, it tracks the entire "chain of custody." (See real-world example below.👇)
- Lineage: How the data was created, potentially including a hierarchy of sidecars for complex datasets built from others. This can track transformations and anonymization procedures.
- Legal rights: Ownership and associated rights like copyright or patents.
- Privacy and protection: Types of privacy information (PII/PHI), relevant regulations, and anonymization techniques used.
- Intended use and restrictions: Legal and safe ways to utilize the data, such as restrictions on public release, downstream sharing, or specific activities.
- Basic information: Generation date, data type/format, generation method, catalog details, etc. (both human and machine-readable). This can even include a "sidecar for the sidecar" for better organization.
How do organizations use sidecars to manage risk?
Third-party data can be a double-edged sword for organizations. While it offers valuable insights, it also comes with its own set of problems. Here are three common third-party data risk problems that sidecars help solve:
-
Privacy concerns and compliance risks: Using data from third parties raises concerns about user privacy and compliance with regulations like GDPR and CCPA. Sidecars can address these concerns in two ways:
- Data anonymization and pseudonymization: Sidecars provide the information necessary to perform critical redaction steps, such as anonymizing or pseudonymizing personal data before being sent to a third-party system. Anonymization removes all personally identifiable information (PII) from the data, while pseudonymization replaces PII with a substitute identifier. This helps protect user privacy while still allowing the third party to analyze the data effectively.
- Data lineage tracking: Sidecars can also track the data lineage, which is a record of where the data came from and how it's been used throughout its lifecycle. This helps companies demonstrate compliance with regulations by providing a clear audit trail that shows they are handling user data responsibly even when crossing company boundaries.
- Data inaccuracies and inconsistencies: Third-party data providers often aggregate business information from various sources, resulting in data inconsistencies and inaccuracies. Sidecars can help organizations validate incoming third-party data reliably and responsibly for appropriate use.
- Data integration challenges: Integrating data from multiple third-party sources can be a headache because the data often comes in different formats and structures. Sidecars can function as data translators in this situation, making it easier and faster to integrate and analyze third-party data alongside the organization's internal data.
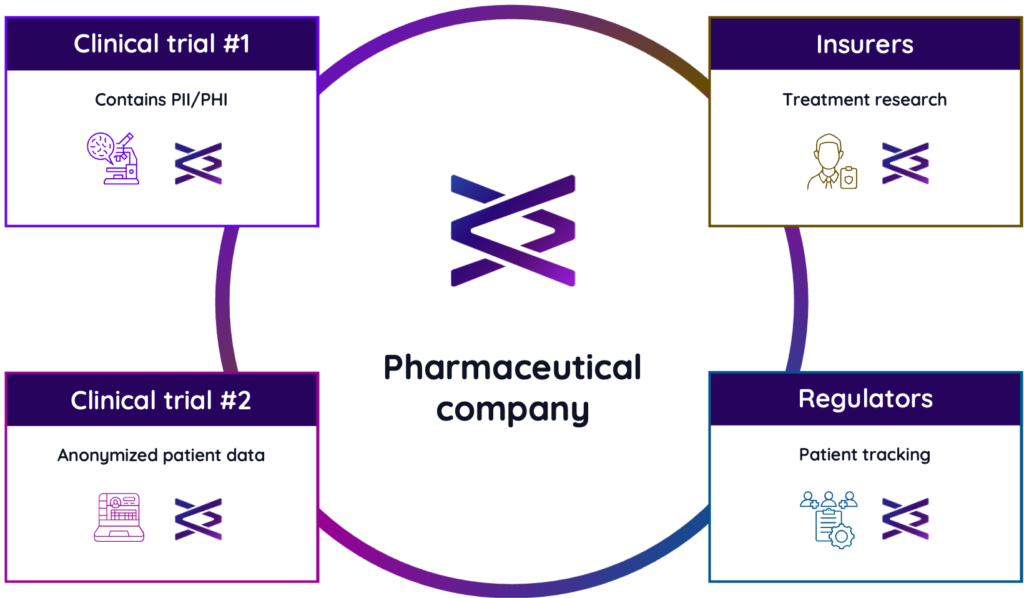
Real-world example: Combining and distributing clinical trial data
Let’s look at a scenario in the healthcare industry to illustrate how sidecars work. Suppose two separate clinical trials are investigating similar drugs. A pharmaceutical company decides to purchase the results from both trials, combining it into a single dataset for marketing purposes. This dataset is then sold to both insurance companies and regulatory bodies. Here’s how sidecars are beneficial in this complex, multi-party scenario:
- Tracking details across each trial dataset: Each of the trial datasets comes with a "sidecar" containing key details about its origin (i.e., which trial it came from), creation date, and so forth. This tells the pharmaceutical company exactly how they can use the contents, in addition to all relevant data-handling requirements.
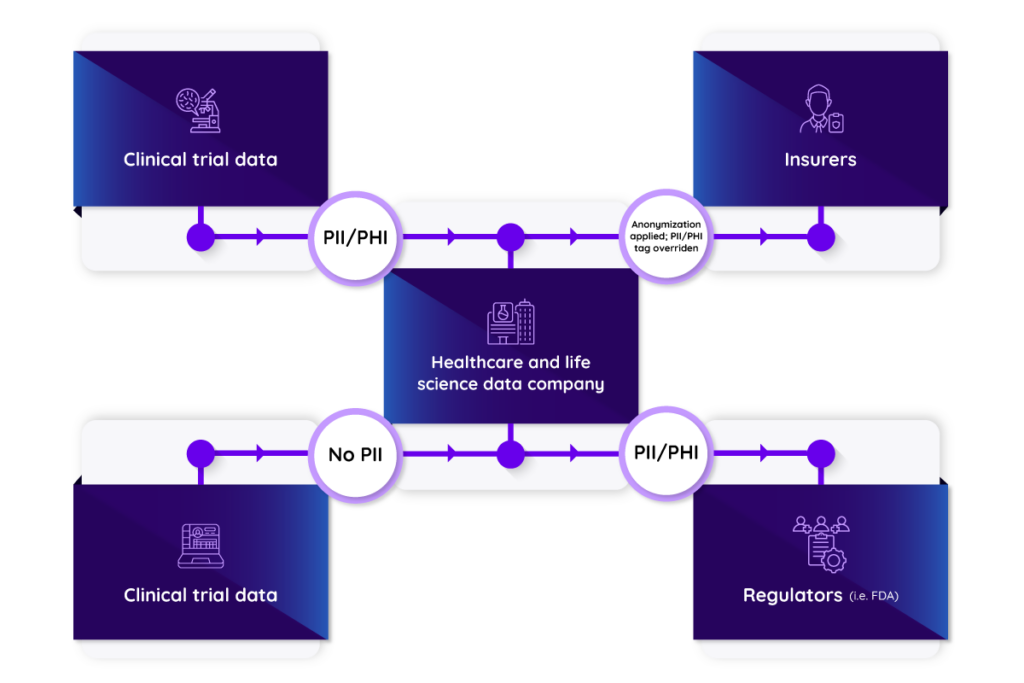
- Combining both datasets into one: Let’s focus this specific example around trial data containing PII (e.g., patient names). In this case, one dataset contains patient names while the other has been anonymized via unique codes. When the pharmaceutical company combines the datasets, both sets of sidecars are merged as well. (Note: this merging process is similar to how the datasets themselves are combined.) The combined sidecar now includes all of the original information from each individual sidecar plus the new details relevant to the combined data set. Since the combined dataset contains some rows with patient names (even though others are anonymized), the combined sidecar will reflect the presence of PII. This ensures complete transparency, regardless of whether some data points are missing (i.e., null values).
- Distributing the combined dataset: The combined dataset, with its merged sidecar, is then sent to regulators, who might need to track down specific patients (and are legally allowed to do so). However, patient names are irrelevant and potentially problematic for insurance purposes. Before sharing the dataset with insurers, the pharmaceutical company will need to redact these details via a technique like tokenization to create a separate version. A new sidecar is then attached to this anonymized version, clarifying that the original PII tag is no longer applicable due to the anonymization process. Importantly, the sidecar for the insurer version still shows the entire processing history. This allows insurers to see that the data originally contained PII and verify that patient names were properly removed.
Sidecars standards: Building a common language
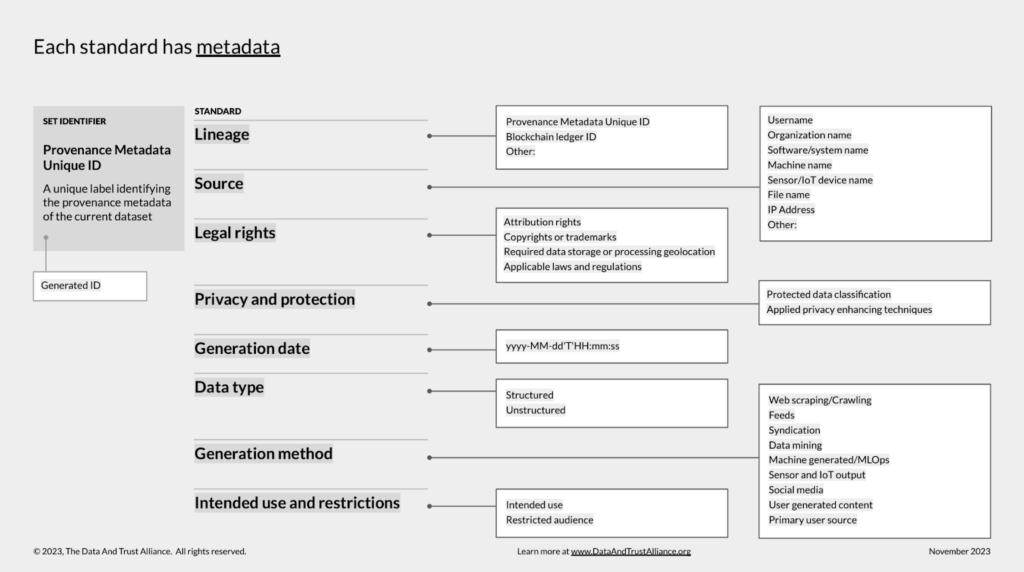
What are universal sidecar standards and why are they important? Think of it this way: If every data producer, conveyor, and consumer created sidecars in their own unique format, it wouldn’t be long before businesses run into “Tower of Babel” translation problems. This is where the Data & Trust Alliance (D&TA) comes in. D&TA is a global group of companies, such as Pfizer, Walmart, Mastercard, and IBM, working together to create universal standards for data sharing. One particular initiative is extremely beneficial for managing risks related to external data sources: the data provenance standard. Think of this standard as an "open-source format" for sidecars. It specifies what information a sidecar should contain, helping companies understand each other's data easily. This standard was created by companies most affected by data risks, such as American Express and Humana, and is designed to help organizations of all sizes determine if external data is trustworthy and usable. Below is a sample of data captured in a sidecar that follows the D&TA standard. It includes mechanisms to capture data lineage, source, generation data, and other critical metadata.
Customizing sidecars and metadata
While the D&TA standard is an excellent starting point, some companies may need to tailor their sidecar contents for unique or industry-specific data-sharing scenarios. For example, companies sharing real-time data may customize their sidecars to add in information about specific data tables or rows. Vendors of sidecar-enabling platforms, such as Vendia, let organizations add further metadata to sidecars to customize and enhance multi-party data sharing, automation, and auditing use cases.
What does a sidecar-enabled solution look like?
Sidecars are great, but what if the information they contain isn't actually accurate? For example, imagine a sidecar containing unknown origin data, rendering it unusable for highly regulated industries such as mortgages or insurance. What’s keeping someone from simply changing the sidecar information to make their data more appealing (and, thus, valuable)? With most data tools, there’s nothing to stop them from doing so. This is why to be truly reliable, sidecars must have the following digital properties:
- Immutable: Information added to a sidecar cannot be deleted.
- Non-repudiable: The source of the information can be definitively proven (i.e., cannot be disputed or denied).
- Tamper-proof lineage: The sidecar and any updates can't be accidentally or intentionally altered. Everyone sees the same, consistent history of the data’s journey.
- Verifiable: The integrity and ownership of the sidecar can be automatically proven—without human intervention—as data moves quickly between machines. Verification happens on the order of milliseconds while key data is being transferred, processed, stored, or exchanged in real time.
If these requirements sound familiar, it’s because they're the same as those for distributed ledgers (also called private blockchains). Distributed ledgers like Vendia are perfect for managing sidecars because they offer all of these capabilities (and more). They're designed for secure business-to-business data sharing where everyone needs to trust the data, no matter where it comes from or goes.