


In Part 1 of this two-part series, we explored the limitations of blockchain, database, and “ignorant” API technology as standalone or unintegrated solutions for real-time, multiparty, enterprise-grade data sharing ecosystems. Now, we’ll take a closer look at how Vendia Share combines these technologies to create a platform that offers the strengths and benefits of each constituent technolog and overcomes their respective limitations. We’ll also explore how customers can adopt our platform for a variety of use cases.
Vendia Share: Smart, “data-aware” APIs across parties and clouds
An ideal real-time data-sharing solution simultaneously needs to offer
- The strong operational, security, and systems isolation of a conventional API
- The security, unlimited long-term data storage, and easy queryability of a conventional centralized database,
- Similar storage capabilities for files
- The cost efficiency and scalability of an event-based architecture
- The “time travel,” guaranteed delivery, and strong ordering guarantees of a real-time streaming solution
- A blockchain’s ability to easily span clouds, companies, and geographies with a consistent data representation
Vendia Share combines API, database, and blockchain technology—all three reimagined as a single, powerful, cloud-native platform. Together, as Vendia Share, they can achieve what no one single technology is capable of in isolation (see Figure 1).
FIGURE 1: Vendia as a venn diagram, combining the best attributes of APIs, databases, and blockchains in a unified SaaS platform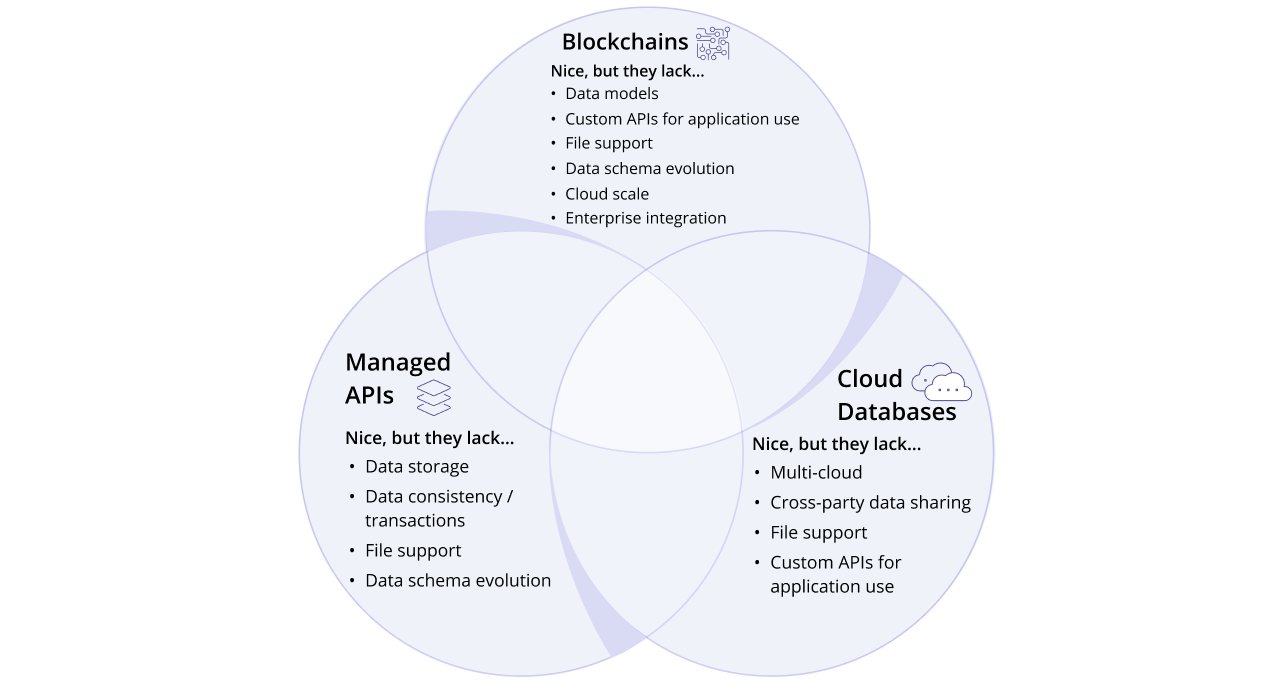
Simplicity by design
Vendia Share makes building data-sharing platforms and applications fast, simple, and secure by design:
- Each participant has a node containing one or more cloud-hosted databases and file stores, capable of 11 9’s of durability storage with unlimited capacity.
- On top of that, a high speed data replication and consensus mechanism emulates a blockchain’s ability to create consistent replicas; the mechanism does so with massive parallelization and cloud-enabled scale and throughput.
- A user-provided data model is used to automatically generate modern GraphQL APIs, including subscriptions that offer real-time streaming and they’re all designed around the application’s data schema. These capabilities include versioning, “time travel,” auditing, and lineage analysis—and they’re available without needing to write even a single line of code. Conventional and familiar database concepts work as expected (e.g., transactions), and files are handled as a built-in feature with full ACID support, just like other data types.
- All services are delivered in SaaS style with zero infrastructure footprint to manage or maintain; fault tolerance is built in (instead of left as an exercise to the customer, as in conventional blockchains).
- Everything is built using scalable and fault tolerant serverles cloud technology, allowing tight cost enveloping, environmental friendliness/a low carbon footprint, and automatic scalability on a per-request basis.
Figure 2 illustrates Vendia’s architecture, combining the best of managed APIs, scalable cloud databases, and enterprise-grade blockchain technology. An operationally and security isolated Node is created in the cloud for each party, including file and scalar data storage. Vendia transparently and automatically synchronizes the data among all nodes using patented blockchain and serverless algorithms. A powerful GraphQL API is generated automatically from (and permanently synchronized with) the application’s data model, including real-time streaming support that keeps each node’s applications consistent with one another. Despite its power, the “no code” approach is simple, with zero infrastructure footprint to manage.
FIGURE 2: Vendia’s “three-legged stool” architecture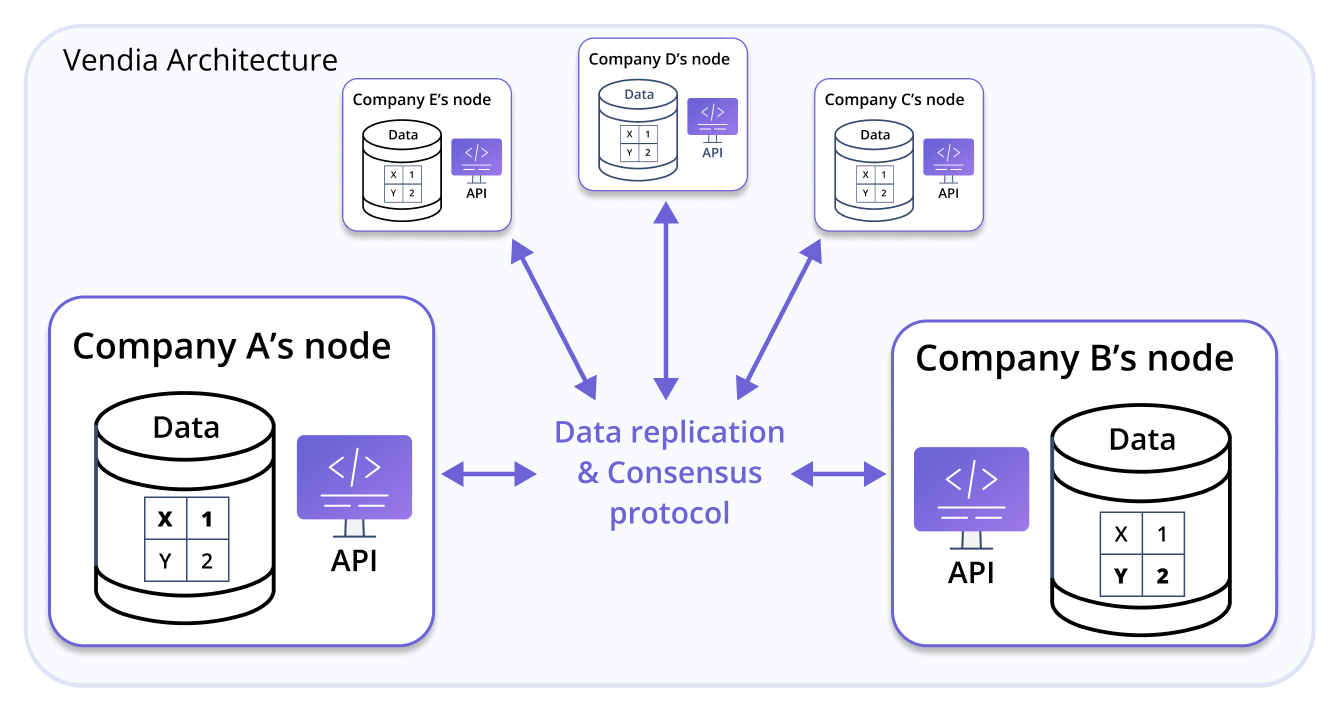
A developer-friendly data model compiler
Combining technologies can sometimes lead to systems that are more difficult to use, especially if their consumers are required to understand the complexity and details of all the constituent pieces. Fortunately, Vendia’s use of a data model compiler actually reduces the set of things a developer needs to learn relative to using APIs, databases, or blockchains in isolation. This puts the complexity in these low-level technologies behind an abstraction barrier as “implementation details” and allows them to stay there (see Figure 3).
FIGURE 3: The data model is used to generate the (1) data storage, (2) file storage, (3) APIs, (4) data-model aware consens and replication layer.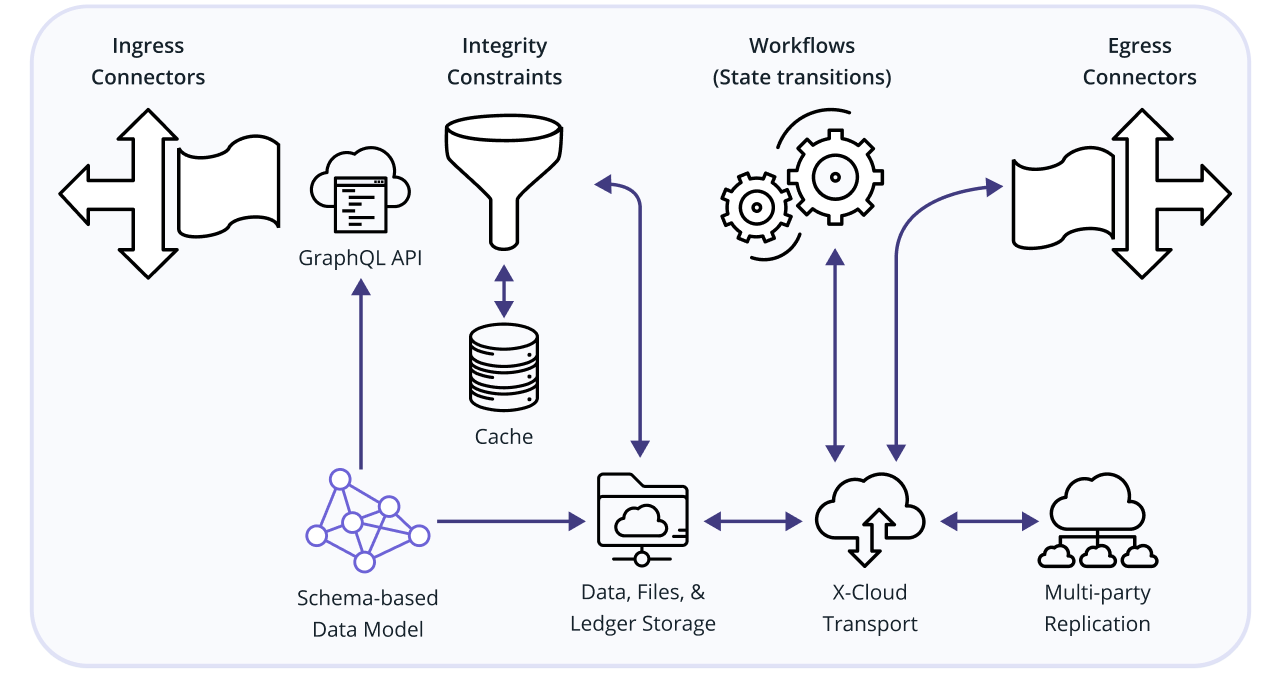
As in a conventional database, the customer brings a data model (i.e.,, a description of what the “tables and columns” should look like). Vendia’s data model compiler turns this description into several outputs:
- A customer-specific storage tier, capable of holding both business and file data
- A consensus protocol that handles data replication across parties and clouds, maintaining consistency and guaranteeing ACID transaction semantics
- A modern, GraphQL API that makes it easy to build create, read, updated, deleted (CRUD) application logic that’s generated from the data model without the need to hand craft
Developers using Vendia Share don’t have to concern themselves with how these elements interact, nor do they have to worry about complex infrastructure hosting or deployment. All the elements above are delivered in SaaS fashion, fully managed and cloud-hosted.
Vendia’s sharing topology creates easy connection with low lift
In addition to the data model itself, there is one another input to the Vendia platform: The sharing topology. Vendia Share makes it easy to connect to business partners and their data, even when they’re on different clouds. That means each party can independently control which public cloud (e.g., AWS or Azure) and region (e.g., us-east-1 or us-west-2 on AWS) they want to reside in. A single party can even deploy multiple nodes, making it easy to create geo-separated, multi-region redundant systems with as little as two lines of configuration.
Additional parties can be invited by sending a secure invitation over email. Vendia handles the heavy lift in the background, automatically creating and deploying the new party’s cloud infrastructure, then syncing its data to reflect the correct subset of data from historical transactions—all without any of the parties needing to write a single line of code.
Finally, Vendia Share makes it easy to configure individual nodes. Through simple configuration settings from the API, CLI, or developer UI, connectors to popular data sources (e.g., Salesforce), data ingress and egress to cloud queuing systems, and smart contracts expressed as cloud functions written in any language are all easy to configure “on chain.”
These configuration-driven mechanisms allow developers to gain powerful ROI with fast time to market. Given a data model, one developer can deploy and connect a production-grade, multi-cloud, multi-region, multi-party solution in under 10 minutes.
Contrast that with typical blockchain and public API deployment cycles that are usually 12-24 months of time with 10-20 developers required per party.
Use case: Co-marketing programs
To see how all this works in action, let’s look at a use case example, marketing data sharing.
Co-marketing programs between two (or more) companies or divisions are a simple but common data sharing need. These programs can happen when companies want to discover common customers or leads to create joint marketing campaigns, loyalty program networks, and more. For two or more divisions within the same company (perhaps especially after merger and acquisition activities), the program might represent multiple Salesforce or other CRM deployments where information is siloed and needs to be converged.
While sharing this information is critical to a successful business outcome, it’s also just as important to avoid _over_sharing. Regulatory requirements, compliance rules, and the simple desire to avoid sharing information about unrelated customers means that the underlying platform needs to make it easy to do all of the following:
- Third-party escrowEnsure the analyses, such as name and/or address matching, are performed in a secure escrow location (also known as a data enclave), rather than by the parties themselves. This avoids one party having to expose all their data to the other in order to perform comparisons or other data analyses or transformations in a conventional, centralized database owned by just one of the parties.
- Access controlsEach party needs an easy way to control what data (i.e., columns and rows) is exchanged with the other party (usually via the escrow/data vault). This is required to ensure that each party retains control over which marketing and customer data is seen by the other party or by any shared analysis. This is also where inconsistent data served up by a conventional API could be dangerous: With compliance regulations, getting a customer’s personally identifiable information (PII) sharing settings wrong (through outdated or inconsistent values) could mean breaking the law.
- Multi-cloud, multi-region, and multi-CRMWhile each party may be happen to operate their portion of this shared workload on a single cloud, it’s often the case that they will each have made differing IT adoption and vendor decisions over time—different clouds, different geographic data center regions, different CRM vendors, etc. The sharing solution cannot assume everyone has migrated to a common vendor and cloud as an a priori requirement, or no progress can be made. Even within a single partner, customer information reside in CRMs, custom application databases, and other locations.
To keep things simple, we’ll assume there are only two parties and that matching (i.e., determining if two customer records are the same person) is based on a customer’s last name and phone number.
The matching logic is simple: If these two fields are equal, then the remainder of the information in each of the matching records is shared with the other party, unless it’s marked as private. The tables below show the data fields for each of our two imagined companies, Acme Corp and CoolTech, Inc.
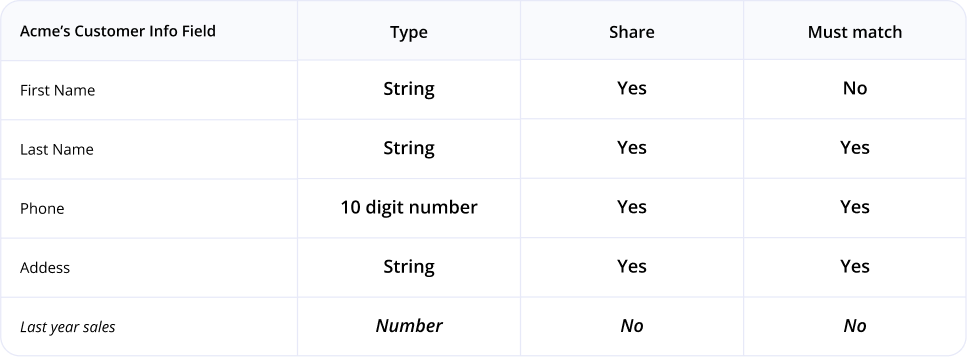

Note under the “Share” column that each of the parties has a field that they wish to remain private, even when a record is found to match (“Last year sales” for Acme and “Number of downloads” for CoolTech).
For fields that don’t match, the resulting record needs to preserve the source of the original information (since the values could differ):

Creating this solution on Vendia Share requires uploading a data model, then creating a smart contract to perform the name comparisons and create the matching records. This can be accomplished easily, in under an hour, resulting in a fully scaled, production-grade deployment.
After that, each party can load their data, and then continue to add data over time. Vendia will continuously process records when either party adds them, automatically scaling up or down to handle varying workloads (see Figure 4).
These systems are all immediately production grade—they come with prebuilt scaling, fault tolerance, and both on-the-fly and at-rest encryption. Each company can set up custom authentication and authorization for as many systems as they like, even using additional nodes if they want their data to span multiple public clouds or regions for additional data backup or fault tolerance.
FIGURE 4: Acme Corp and CoolTech share records across time, accumulating a shared set of records and a real-time single source of truth.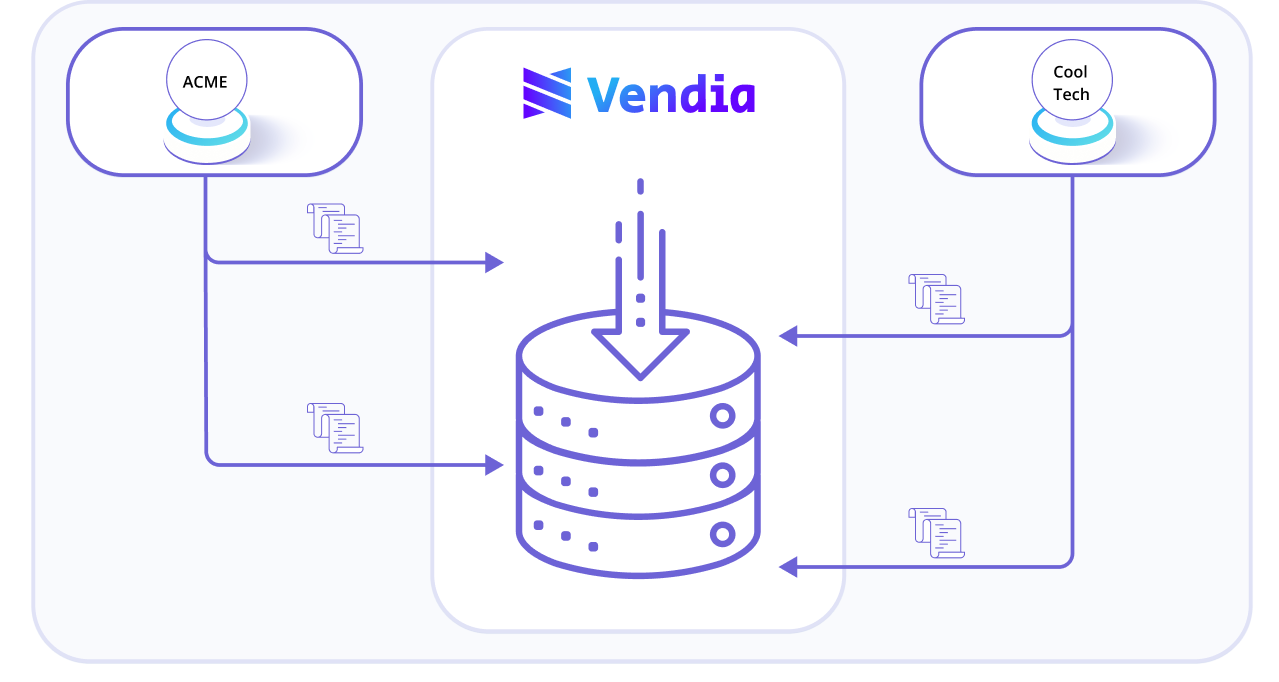
Changes over time: Data model updates
Many application systems fail to recognize a key aspect of business: The data needed to drive outcomes changes over time.
One of the key strengths of Vendia Share is that it is designed not just as a one-time deploy solution, but as a system that supports companies as they adjust or add to the data they need over time.
For instance, in our marketing use case above, Acme Corp and CoolTech might decide to move beyond simple co-marketing and create a shared customer loyalty program. Now, they’ll need to start tracking customer loyalty points and related information, too.
To do that, they need to modify their data schema to incorporate additional fields (e.g., loyalty point account tracking). If the data model were fixed, this would be impossible— they’d have to throw away their existing data sharing solution and start over! Fortunately, that’s not the case with Vendia Share.
Vendia Share’s sophisticated schema compiler can understand schema additions and changes over time. It can incrementally modify the production-grade deployment to add new fields to existing data types as well as entirely new data types to the existing solution—without compromising the security or integrity of existing data and without requiring API clients to be rewritten.
That latter point is especially crucial: If APIs have been shared with mobile or web clients, changing those APIs could break every app instantly. To avoid that, Vendia Share uses a sophisticated GraphQL API that is evolution-aware, and its schema compiler automatically detects and prevents any changes that could damage API clients.
The result? Changes are simple, seamless, and guaranteed to be safe for all clients.
That kind of guarantee is the holy grail of product and business owners ( and the bane of development teams who frequently struggle to achieve it). With Vendia, it’s impossible not to achieve that guarantee.
Changes over time: Partner updates
In addition to data model changes, there’s another important way our use case example could evolve: The business relationships themselves change. For instance, in our simple example we had only two companies sharing data. What happens when four new partners join this emerging loyalty program? Will that mean rewriting the entire application?
Fortunately, Vendia Share models business partnership sharing directly, making adding new parties as easy as sending them an email invitation. Vendia’s secure data replication platform will automatically deploy the new participant’s cloud resources automatically, with no coding required, into their cloud and geographic region of choice, then seamlessly replicate all required data to them. If a business partner should need to leave the loyalty program, removing them is equally simple, and they can take their accumulated data (though of course no data created post their departure) with them.
And while adding parties is most commonly thought of as a way to model business relationship changes, the same feature functionality can also be used by the existing parties for important IT outcomes. Additional nodes can be added to create multi-region backups, multi-cloud resilience, or additional operational boundaries or geographic scaling.
Conclusion
APIs, cloud databases, and blockchains are each an important building block of modern IT infrastructure but, on their own, they lack the capabilities to create real-time data connectivity and sharing solutions.
Vendia combines all three technologies in its platform Vendia Share, offering customers an easy, secure, and scalable way to create modern IT outcomes as simply as they create a new database table today.
With nothing more than a data model, Vendia customers can easily achieve a multi-party, multi-cloud, multi-region solution able to connect their applications and data with other divisions, other companies, and other clouds…all without having to write code or manage servers.
Vendia’s customers use these capabilities to create secure, compliant solutions for loyalty programs, ticketing, financial settlements, file and media sharing, and other critical outcomes where accurate, real-time operational data is critical.
Learn more
To learn more about how Vendia can make API development and management easier for data-driven applications, download our Smart APIs ebook.
To explore modern application design that leverages modern data platforms, read about the Lean App movement on Vendia’s blog.
To explore customer use cases, visit Vendia’s product page.
To see if your use case could benefit from a data-centric API approach or a data platform, contact Vendia.