


Ever wonder what those "Merkle trees" are, mentioned in our posts (like this one on centralized vs. decentralized data? They're the secret weapon for securing data! Dive deeper and discover how they work.
You’d be forgiven for thinking a Merkle tree is something you’d find in a fancy arboretum – even many computer science graduates aren’t familiar with this particular data structure. In today's world of ever-expanding data, keeping it secure and accurate is crucial. Enter Merkle trees, clever structures that fingerprint an entire dataset. This lets you quickly check if data has been tampered with, saving time and boosting trust – even across business partners. Read on to learn more about Merkle trees and uncover how they can empower your data security strategy.
The Challenge of data integrity: from books to bank balances
Companies manage vast amounts of complex data – think detailed spreadsheets, patient records, intricate construction blueprints, a company’s patents, or a cloud storage bucket within a specific point of time. To grasp the challenge of ensuring the integrity and accuracy of data, let’s try to analyze Tolstoy’s massive novel, War and Peace, as an example. Let’s start simple – the first sentence of War and Peace, in its English translation, goes: Well, Prince, so Genoa and Lucca are now just family estates of the Buonapartes. Suppose we have a few different readers of the novel who want to be in agreement that they’re reading the same version of it (for example, the same version of the same translation by the same publisher). How do we guarantee that everyone in our book club has the exact, correct version of a book? Here are a few strategies:
- Attestation: One member could take the lead in confirming the book's specifics (edition, ISBN, etc.) and noting them for the group.
- Contracts: The group could work together to verify the correct version. This could involve comparing copies or reaching out to a trusted source if there's any uncertainty.
- Authoritative Reference: If needed, the group could consult a reliable authority to determine the definitive version. This could be a university's literature department, the publisher's website, or a reputable online book database.
Let's amplify the challenge: Suppose a new book the size of War and Peace gets written daily. In fact, how about we make it 100 books a day, each of which is 100 times longer than War and Peace, and we want absolute assurance that not even a single word is out of order. Now, swap out "words" for "bank account balances." Suddenly, even a misplaced comma is disastrous! Traditional verification methods crumble under this volume and sensitivity. It's clear we need machines and algorithms to safeguard our data with the utmost precision.
Hashes: The digital fingerprint for data
Just as libraries rely on titles and call numbers to organize their collections, computers use hashes to uniquely identify data. A hash is like a short, algorithmically generated summary of content. Unlike author-assigned titles which could be prone to duplication, hashes avoid accidental duplicates, making them perfect for representing massive quantities of information. Let's break down the key properties of a good hash:
- Short and Sweet: Hashes act as quick references. A hash should be much smaller than the original data for efficiency.
- Scalable: We need enough unique hashes to represent a vast dataset and its potential growth.
- Collision-resistant: Ideally, even minor changes in the data should produce a completely different hash, ensuring change detection.
- Easy to Compute: Computing hashes shouldn't be a computationally expensive process.
Hashes in action
Imagine assigning a unique hash to War and Peace and every other novel. You now have something like this:
- War and Peace: 1937598265781103
- Slaughterhouse Five: 0091572947392766
- The Sun Also Rises: 8939275561040772
We've developed a universal language for discussing books, managed entirely by machines! By generating unique hashes for each book, we can unlock exciting possibilities. For instance, if a publisher alters a book's text (intentionally or not), even minor changes will produce a new hash. This provides an objective way to verify a book's integrity, empowering everyone to agree on the facts.
Hashes: Good, but not perfect
Hashes tell us only if something has changed, not what or how much. Also, while they handle individual pieces of data well, they're less helpful for managing large collections. Comparing hashes for every book in a shipment is still an unwieldy process. This begs the questions - how can we leverage hashing in order to accurately search large volumes of data? This is where Merkle trees come into the picture.
Introducing Merkle trees
While hashes fingerprint individual pieces of data, Merkle trees allow us to create "fingerprints of fingerprints" for entire collections. Imagine a Merkle tree for our library of many novels. Each book is a leaf, represented by its hash. Branches of the tree combine hashes of groups of books, ultimately leading to a final root hash that represents the entire library, in the correct order.
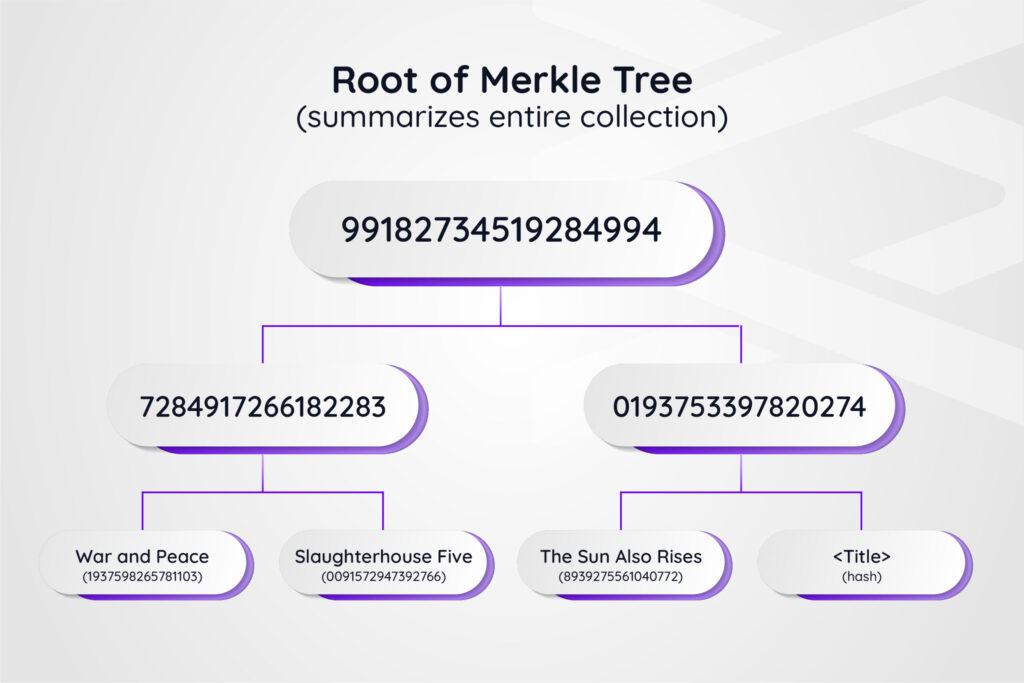
Figure 1: A collection of novels in a Merkle tree
The magic here is that if even one word in one book changes, the entire tree's structure changes, so the root hash becomes different - instantly alerting us to tampering.
Merkle Trees in Action
Let's see how Merkle trees help us in practice:
- Short and Sweet: Hashes act as quick references. A hash should be much smaller than the original data for efficiency.
- Scalable: We need enough unique hashes to represent a vast dataset and its potential growth.
- Collision-resistant: Ideally, even minor changes in the data should produce a completely different hash, ensuring change detection.
- Easy to Compute: Computing hashes shouldn't be a computationally expensive process.
Zooming In: Granular Change Detection
Merkle trees offer incredible flexibility, and their structure is key to pinpointing changes. We generate them with words as "leaves", then progressing through sentences, pages, chapters, and the entire book. If two books share the same "root hash", we know their contents are identical down to every word. But what if the root hashes differ? That's when we start digging! We compare the chapter-level hashes. Imagine all chapters match except for Chapter 1 – that's our focus. Next, we check page-level hashes within that chapter – if some are different, we know which pages need exploring. We can even repeat this down to the sentence level! This step-by-step approach lets us quickly narrow down the search, ultimately revealing even a single missing comma. Computer scientists call this efficient, granular search method a "recursive search algorithm."
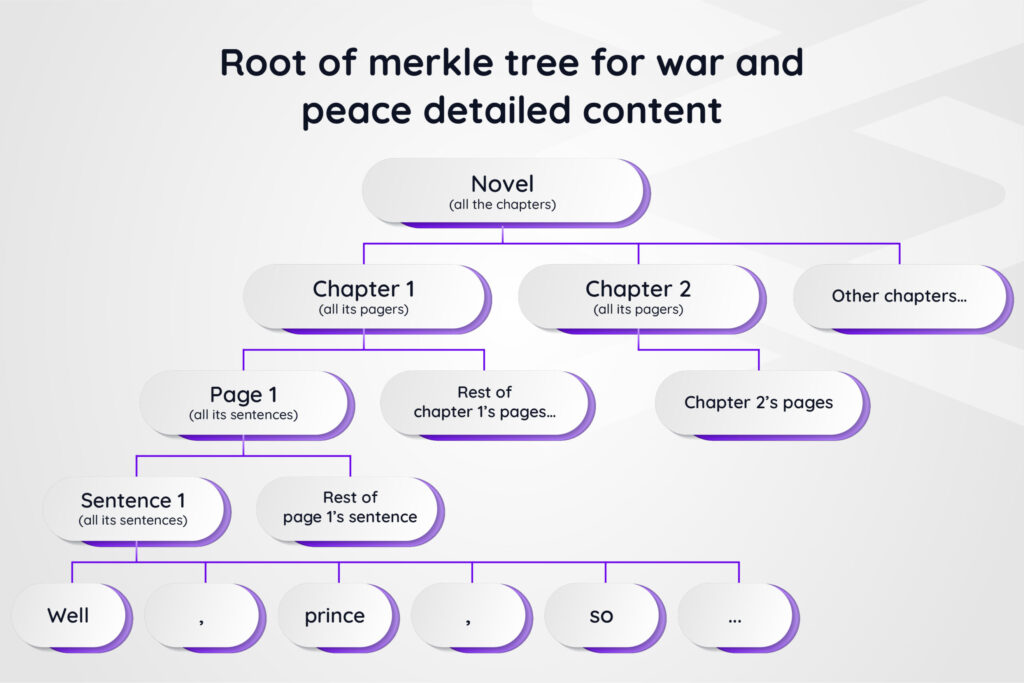
Figure 2: Merkle tree for the content of War Peace, with granularity down to individual words
Merkle Trees in the Real World
While the power of Merkle trees shines through our literary analogy, their reach extends far beyond dusty libraries. They're incredibly critical in safeguarding critical corporate data, protecting it from both accidental glitches and malicious intent. Their versatility is remarkable – they can secure structured data in databases, files nestled within the cloud, even the constant flow of streaming data. Merkle trees truly come into their own within the realm of blockchains. Think of each block in a blockchain as containing its own mini Merkle tree, safeguarding its data. The blockchain itself then becomes a vast, ever-evolving Merkle tree! This ingenious integration ensures not only the integrity of data at a specific moment in time but also its entire history. Companies can now collaborate securely because the blockchain's very structure instills trust, even when the content grows and changes with each passing minute. From humble beginnings as 'digital fingerprints' to the guardians of vast datasets and revolutionary blockchains, Merkle trees are astonishingly elegant tools. In a world driven by data, Merkle trees are the quiet enforcers of accuracy and trust – pretty cool stuff indeed for something as basic as a tree of hashes! If you’d like to see a practical application of Merkle trees, check out our blog that showcases how Merkle trees offer a solution for guaranteeing transaction lineage and safeguarding data history in a real-time data sharing scenario.